Pegasus GEO
背景
在 Pegasus 中,当用户数据属于 POI (Points of Interest) 数据,其中含有地理信息,比如 value 中包含有经纬度,需要 Pegasus 提供接口进行 GEO 特性的支持。比如给定一个中心点坐标和一个半径,查找这个范围内的所有数据;给定两条 POI 数据的 hashkey 和 sortkey,求这两条数据地理上的距离等。
Pegasus 的 GEO (Geographic) 支持使用了 S2 库, 主要用于将二维地理坐标(经度 + 纬度)与一维编码的相互转换、基于圆形的范围查询、Hilbert 曲线规则等特性。
本文将说明在 Pegasus 中是如何充分利用 S2 的特性,并结合 Pegasus 的数据分布与数据存储特性,来支持 GEO 特性的。
关于 S2 的实现原理请参考 S2官网。
坐标转换
在 S2 中,可以把二维经纬度编码成一维编码,一维编码由两部分组成:立方体面、平面坐标编码,比如:
经纬度(116.334441, 40.030202)的编码是:1/223320022232200331010110113301(总共32位),这个编码在 S2 中称为 CellId。
其中:
- 首位的
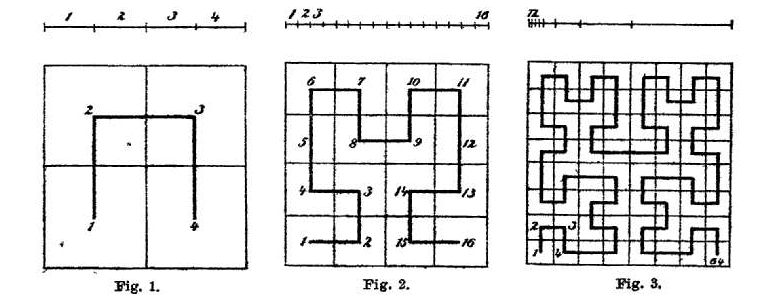
1代表地球立方体投影的面索引,索引范围是0~5,如下图所示:

/是分隔符223320022232200331010110113301(30位),是经纬度坐标经过一系列转换得到的编码,具体转换过程这里不详细描述。需要指出的是,这是一个名为 Hilbert 曲线编码,它最大的特点是具有稳定性、连续性。
S2 中的 Hilbert 曲线编码:
- 编码可以看作是一个 4 进制的数值编码
- 编码由左往右按层进行,最多 30 层
- 一个编码代表地理上的一个方块区域,编码越长,区域越小
- 完整编码是前缀编码的子区域,每个父区域由4个子区域组成,比如
00,01,02,03是0的子区域,且前者的区域范围的并集就是后者的区域范围 - 在数值上连续的值,在地理位置上也是连续的,比如
00和01的区域范围是相邻的,0122和0123的区域范围也是相邻的
编码精度
S2 中的 Hilbert 曲线编码由 30 位组成,每一位代表一层划分。下表是各层单个 cell 的面积和 cell 个数。
| level | min area | max area | average area | units | Number of cells |
|---|---|---|---|---|---|
| 00 | 85011012.19 | 85011012.19 | 85011012.19 | km^2 | 6 |
| 01 | 21252753.05 | 21252753.05 | 21252753.05 | km^2 | 24 |
| 02 | 4919708.23 | 6026521.16 | 5313188.26 | km^2 | 96 |
| 03 | 1055377.48 | 1646455.50 | 1328297.07 | km^2 | 384 |
| 04 | 231564.06 | 413918.15 | 332074.27 | km^2 | 1536 |
| 05 | 53798.67 | 104297.91 | 83018.57 | km^2 | 6K |
| 06 | 12948.81 | 26113.30 | 20754.64 | km^2 | 24K |
| 07 | 3175.44 | 6529.09 | 5188.66 | km^2 | 98K |
| 08 | 786.20 | 1632.45 | 1297.17 | km^2 | 393K |
| 09 | 195.59 | 408.12 | 324.29 | km^2 | 1573K |
| 10 | 48.78 | 102.03 | 81.07 | km^2 | 6M |
| 11 | 12.18 | 25.51 | 20.27 | km^2 | 25M |
| 12 | 3.04 | 6.38 | 5.07 | km^2 | 100M |
| 13 | 0.76 | 1.59 | 1.27 | km^2 | 402M |
| 14 | 0.19 | 0.40 | 0.32 | km^2 | 1610M |
| 15 | 47520.30 | 99638.93 | 79172.67 | m^2 | 6B |
| 16 | 11880.08 | 24909.73 | 19793.17 | m^2 | 25B |
| 17 | 2970.02 | 6227.43 | 4948.29 | m^2 | 103B |
| 18 | 742.50 | 1556.86 | 1237.07 | m^2 | 412B |
| 19 | 185.63 | 389.21 | 309.27 | m^2 | 1649B |
| 20 | 46.41 | 97.30 | 77.32 | m^2 | 7T |
| 21 | 11.60 | 24.33 | 19.33 | m^2 | 26T |
| 22 | 2.90 | 6.08 | 4.83 | m^2 | 105T |
| 23 | 0.73 | 1.52 | 1.21 | m^2 | 422T |
| 24 | 0.18 | 0.38 | 0.30 | m^2 | 1689T |
| 25 | 453.19 | 950.23 | 755.05 | cm^2 | 7e15 |
| 26 | 113.30 | 237.56 | 188.76 | cm^2 | 27e15 |
| 27 | 28.32 | 59.39 | 47.19 | cm^2 | 108e15 |
| 28 | 7.08 | 14.85 | 11.80 | cm^2 | 432e15 |
| 29 | 1.77 | 3.71 | 2.95 | cm^2 | 1729e15 |
| 30 | 0.44 | 0.93 | 0.74 | cm^2 | 7e18 |
数据存储
在 Pegasus 中,数据存储的 key 是 hashkey + sortkey:hashkey 用于确定数据所处的 partition,同一 hashkey 的数据存储在同一 Replica Server 的一块逻辑连续的区域中,sortkey 用于在这块区域中做数据排序。
经纬度经过坐标转换得到一维编码 CellId 后,就可以把这个一维编码作为 key 存储起来做GEO索引数据了,Pegasus 将这个一维编码拆分成 hashkey 和 sortkey 两部分,可以根据实际的用户场景采取不同的位数划分策略。
GEO 索引数据独立于原始数据,两类数据存储在不同的 Pegasus 表中,通过 GEO Client 做数据同步,同时支持原生 Pegasus API 和 GEO API 的访问。
所以,在使用 Pegasus GEO 特性时,需要创建两个 Pegasus 表,一个是原始表,用于存储用户写入的原始数据,一个是 GEO 索引表,用于存储 GEO Client 自动转换原始数据生成的 GEO 索引数据。
hashkey
hashkey 由一维编码的前缀构成。比如在一个用户场景中,将 hashkey 长度定为14(1位face,1位分隔符/,12位Hilbert编码)能取得更好的性能。
那么,最小搜索层就为12
CellId
|1/223320022232..................|
|-------------32 bytes-----------|
|---14 bytes--|
hashkey
sortkey
为了满足不同半径范围、不同精度的查询,我们把 CellId 剩下的 18 位全部放到 sortkey 中。
- 在进行较大半径的范围的查询时,取更少的 sortkey 位数(对应的 CellId 更短)作为前缀,进行数据 scan 查询,这样可以减少数据 scan 的次数
- 在进行较小半径的范围的查询或点查询时,取更多的 sortkey 位数(对应的 CellId 更长)作为前缀,进行数据 scan 查询,这样可以减少数据 scan 的范围
这可以在不修改底层存储数据的前提下,让应用层保持比较高的灵活性。
查询相同地理区域内(例如一个圆形区域)的数据时,使用短 CellId 查询数据查询的范围更大,查询的次数更少,但得到的在区域外的无用数据更多。而使用长 CellId 查询数据查询的范围更小,得到的在区域外的无用数据更少,但查询的次数更多
参考:S2 coverings
尽管在第30层时,cell 的面积已经足够小( < 1cm^2),但仍有可能两条数据落在同一个 cell 里,所以需要在 CellId 编码的基础上,解决 key 冲突问题。Pegasus 将原始表的 hashkey 和 sortkey 联合起来,追加在 GEO 索引表的 sortkey 之后。
CellId
|1/223320022232200331010110113301|
|-------------32 bytes-----------|
|---14 bytes--||-----18 bytes----||--原始hashkey--||--原始sortkey--|
|-GEO hashkey-||-------------------GEO sortkey-------------------|
value
使用 Pegasus GEO 特性时,所存储的 value 必须能够解析出经纬度,具体的解析方式参考Value extractor。
GEO 索引表的 value 跟原始表的 value 完全相同,因此会存在一份冗余数据,使用空间换时间的方式避免二次索引。
如果确实有在单条 POI 中存储较大数据的需求,又想节省磁盘空间,可以手动实现二次索引,即在 GEO value 中存储二级索引的 key,再在另外的表中存储实际的大 value。
数据更新
set
set 操作会同时更新上述两个表的数据,即 Pegasus 原始表数据和 GEO 索引表数据,数据构造方式也如上所述。
set操作的 hashkey,sortkey 是用户自己的格式,使用 GEO API 时并不做约束。两个表的数据同步对用户是透明的,由 GEO Client 自动完成。
使用 Redis GEO API 时, 参考 GEO API。
在 Pegasus 实现中,set操作会首先尝试读取出已有的数据,如果数据不存在,则直接向两个表中写入数据。如果数据已存在,会先将老的 GEO 索引数据清理掉后,再写入新数据。因为新老数据的索引数据 <hashkey, sortkey> 可能是不一样的(即新老 value 根据 extractor 解析得到的经纬度不一样),若不清理,GEO 索引表中将存在垃圾数据,造成磁盘空间的浪费,也会在进行地理范围查询时(即GEORADIUS)查到脏数据。
del
del操作会同时删除两个表的数据,原理同上。
数据查询
设计
地理范围查询会转换成 Pegasus 的多次 scan 操作,一次 scan 对应为一个 CellId 范围内的所有数据扫描。 要想获得更高的性能,就需要减少 scan 的总次数和单次 scan 的数据量,也就是需要减少总的 CellId 数量和单个 CellId 的面积。
比如,在做如下红色圆圈的范围查询时,可以采取蓝色方框的 CellId 查询集合:
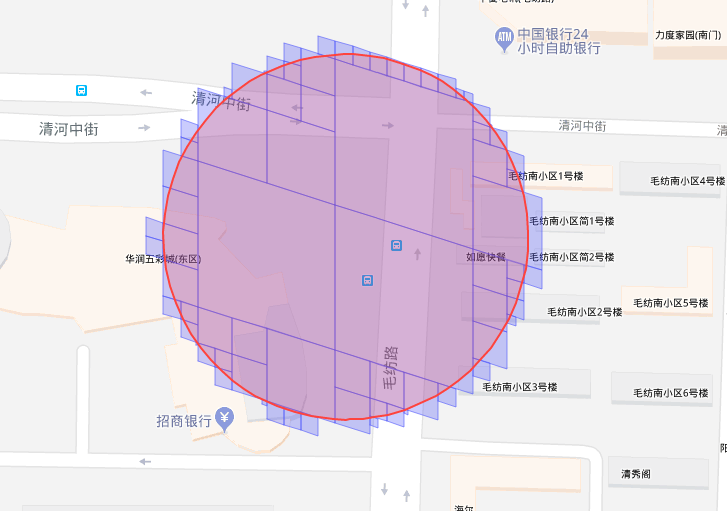
虽然这样的结果更精确,但参与计算的 CellId 的数量更多,带来的 client-server RPC 次数更多,网络开销更大,延迟更高。此外,在真实的应用场景中,太小的 CellId 可能并没有数据,但依然会消耗一次 RPC。
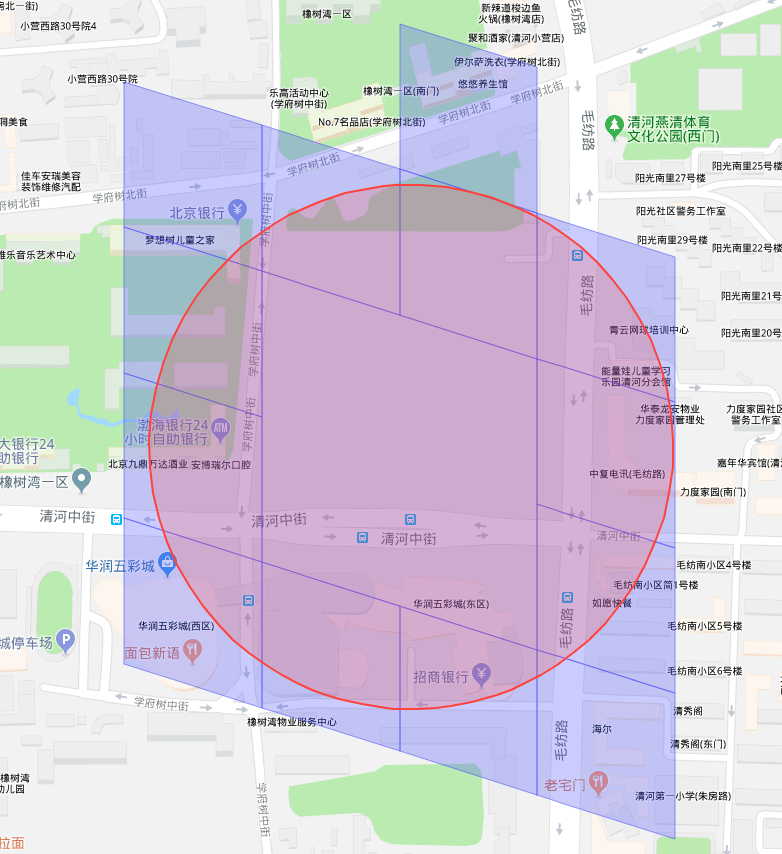
所以,在当前的 Pegasus 实现中,只联合使用两层 cell,最小搜索层和最大搜索层, 以 12 层和 16 层为例,得到的 CellId 查询集合如蓝色方框所示:
查询流程
以search_radial为例,此 API 的意义是给定点和半径,查询出该圆形区域内的所有 POI 数据。
这里我们只讨论圆形区域的数据查询,其他的比如多边形区域的思想是类似的。
使用 S2 API 来查询覆盖了给定区域的 CellId 集合:
// Returns an S2CellUnion that covers the given region and satisfies the current options.
S2CellUnion GetCovering(const S2Region& region);
search_radialAPI 有两个重载函数,一个是输入经纬度,一个是输入 hashky 和 sortkey,后者是通过 key 从原始表中取到 value,解析出 value 中的经纬度,再转调前者。
查询流程如下:
- 根据经纬度、半径,求出 S2Cap 圆形区域
C - 根据圆形区域、指定的
最小搜索层,通过GetCovering,求出在最小搜索层上的 CellId 集合 - 遍历这些 CellId,判断 CellId 区域跟圆形区域
C的关系- 全覆盖:取该 CellId 内的所有 POI 数据
- 半覆盖:将该 CellId 按
最大搜索层继续拆分,判断拆分后的 sub_CellId 区域与圆形区域C的关系- 覆盖/相交:取该 sub_CellId 的所有 POI 数据
- 不相交:丢弃
最小搜索层,最大搜索层的配置参考后文。最小搜索层的 CellId 长度确定 GEO 索引表中数据的 hashkey 长度。
取一个 CellId 的所有 POI 数据时,会根据上文的 key 构造规则,构造一对包含这个 CellId 所有数据的start_sortkey,stop_sortkey,再使用Pegasus的scan接口进行数据搜索。
- 对于
3.1步取到的最小搜索层CellId 的编码,它也就是 GEO 索引表中的 hashkey,调用scan(CellId, "", "")查询所有 POI 数据- 比如,一个 12 层的 cell
1/223320022232被区域完全覆盖,则调用scan("1/223320022232", "", "")查询所有 POI 数据
- 比如,一个 12 层的 cell
- 对于
3.2.1步取到的 sub_CellId 集合,hashkey 是它的前缀,调用scan(sub_CellId_common_prefix, sub_CellId1, sub_CellId2)搜索 POI 数据- 其中,sub_CellId_common_prefix 是 sub_CellId 集合的公共前缀,长度是 hashkey 的长度。sub_CellId1 和 sub_CellId2 之间连续的所有 sub_CellId 都在集合中,字符串长度是
最大搜索层减最小搜索层的长度 - 比如,一个12层的 cell
1/223320022232的子区域0001,0002,0003,0100才跟目标区域相交时,则调用scan("1/223320022232", "0001", "0003")、scan("1/223320022232", "0100", "0100")
- 其中,sub_CellId_common_prefix 是 sub_CellId 集合的公共前缀,长度是 hashkey 的长度。sub_CellId1 和 sub_CellId2 之间连续的所有 sub_CellId 都在集合中,字符串长度是
得到scan的结果后,还需处理:
- 计算距离:因为 CellId 可能只与输入区域部分重合,该点若在区域外,需丢弃
- 排序:当有升序/降序要求时
灵活性
由于我们存储了完整的 30 层 CellId,所以在实际使用中,可以根据地理数据密度、网络 IO、磁盘 IO等情况调整最大搜索层。
最大搜索层默认为16。
API方式
dsn::error_s set_max_level(int level);
配置文件方式
[geo_client.lib]
max_level = 16
不变性
由于最小搜索层确定了 GEO 索引数据的 hashkey 的长度,数据一旦写入 Pegasus 后,最小搜索层便不可修改了,因为数据已按这个 hashkey 长度规则固化下来。
若要修改,需要重建数据。
默认为
12。
[geo_client.lib]
;NOTE: 'min_level' is immutable after some data has been inserted into DB by geo_client.
min_level = 12
Value extractor
目前 Pegasus 支持从固定格式的 value 中解析出经纬度。经纬度以字符串形式嵌入在 value 中,以|分割。
比如:value 可以是.*|115.886447|41.269031|.*,经纬度在 value 中的索引由配置文件中的latitude_index和longitude_index确定。
API & Redis Proxy
Pegasus GEO 特性的使用有两种方式,一是直接使用 C++ GEO Client,二是使用 Redis Proxy。
C++ GEO client代码中有详细的 API 说明。
配置文件
Redis Proxy 的使用请参考Redis适配。
GEO API 添加的配置文件如下:
[geo_client.lib]
;NOTE: 'min_level' is immutable after some data has been inserted into DB by geo_client.
min_level = 12
max_level = 16
; 用于经纬度的extractor
latitude_index = 5
longitude_index = 4
批量数据导入
在一些使用场景中,用户已经有 value 中包含经纬度的原始数据表,需要构建上述的 GEO 索引表,则可以使用 shell 工具里的copy_data功能来实现。比如:
在进行copy_data操作之前,目标集群以及两个目标表(即,原始数据表temp,GEO 索引数据表 temp_geo)都需要提前创建好。
copy_data -c target_cluster -a temp -g
数据导入完成后就可以搭建 Redis Proxy 了,具体的说明参考Redis适配,需要注意的是配置项:
[apps.proxy]
; if using GEO APIs, an extra table name which store geo index data should be appened, i.e.
arguments = redis_cluster temp temp_geo
Benchmark
测试环境
服务器配置
- CPU:E5-2620v3 * 2
- 内存:128GB
- 磁盘:容量 480GB SSD * 8
- 网卡:带宽 1Gb
集群配置
- Replica Server 节点数:5 个
- 版本:v1.9.2
- 测试表的 Partition 数:128
- 单条数据大小:120 字节
测试接口
void async_search_radial(double lat_degrees,
double lng_degrees,
double radius_m,
int count,
SortType sort_type,
int timeout_ms,
geo_search_callback_t &&callback);
参数
- lat_degrees、lng_degrees:每次都选取北京五环内的随机点
- radius_m:如下表第一列,单位米
- count:-1,表示不限定结果数量
- sort_type:不排序
测试结果
| Radius(m) | P50(ms) | P75(ms) | P99(ms) | P99.9(ms) | Avg result count | QPS per node |
|---|---|---|---|---|---|---|
| 50 | 1.63071622 | 1.84607433 | 4.04545455 | 6.28 | 9.4608 | 740.287 |
| 100 | 1.76 | 2.33614794 | 5.4 | 6.45319149 | 38.0296 | 656.66 |
| 200 | 2.41017042 | 3.31062092 | 6.41781609 | 9.60588235 | 154.3682 | 536.624 |
| 300 | 3.30833333 | 4.21979167 | 9.4310559 | 18 | 350.9676 | 434.491 |
| 500 | 5.07763975 | 6.84964682 | 16.84931507 | 21.78082192 | 986.0826 | 347.231 |
| 1000 | 12.28164727 | 18.70972532 | 43.18181818 | 57.049698 | 3947.5294 | 204.23 |
| 2000 | 35.78666667 | 54.7300885 | 108.7331378 | 148.616578 | 15674.1198 | 98.7633 |