Pegasus GEO
Background
In Pegasus, if the user data is POI (Points of Interest) data, which contains geographic information, such as longitude and latitude in value, and users require Pegasus to provide interfaces to support GEO features. For example, given a center point coordinate and a radius, search for all data within this range. Given the hashkey and sortkey of two POI data, calculate the geographical distance between these two pieces of data.
Pegasus’s GEO (Geographic) support uses S2 library, mainly used for converting two-dimensional geographic coordinates (longitude+latitude) to one-dimensional encoding, range queries based on circles, Hilbert curve rules, and other characteristics.
This article will explain how to fully utilize the characteristics of S2 in Pegasus, and combine the data distribution and storage characteristics of Pegasus to support GEO features.
Please refer to the S2 official website for the implementation principle of S2.
Coordinate transformation
In S2, two-dimensional longitude and latitude can be encoded into one-dimensional encoding, which consists of two parts: face cells and plane coordinate encoding, such as:
The encoding of two-dimensional coordinate (116.334441, 40.030202) is: 1/223320022232200331010110113301(32 bytes), it is called CellId in S2.
- The first
1represents the face cell index of the Earth cube projection, with an index range of 0~5, as shown in the following figure:

/is a delimiter223320022232200331010110113301(30 bytes), is the encoding obtained through a series of transformations of latitude and longitude coordinates, and the specific transformation process is not described in detail here. It should be pointed out that this is a Hilbert curve encoding, which is characterized by stability and continuity.
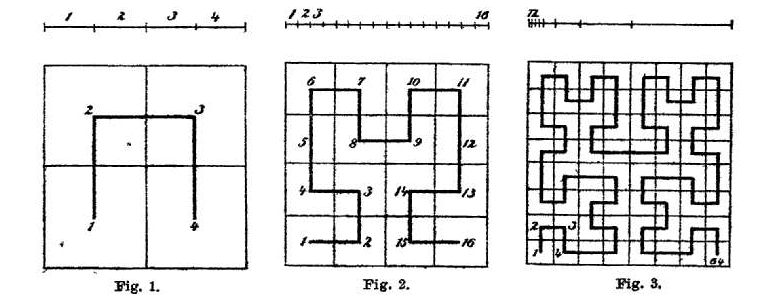
Hilbert curve encoding in S2:
- Encoding can be seen as a 4-digit numerical encoding
- Encoding is done level by level from left to right, with a maximum of 30 levels
- A code represents a geographic block area, and the longer the code, the smaller the area
- The complete encoding is a sub-region of its prefix encoding, with each parent region consisting of four sub-regions. For example,
00,01,02, and03are sub-regions of0, and the union of the sub-regions equal to the region of the prarent’s. - Numerically continuous values are also geographically adjacent, for example, the range of regions for
00and01is adjacent, and the range of regions for0122and0123is also adjacent
Encoding accuracy
The Hilbert curve encoding in S2 consists of 30 bytes, each representing a level partition. The following table shows the area and number of individual cells in each level.
| level | min area | max area | average area | units | Number of cells |
|---|---|---|---|---|---|
| 00 | 85011012.19 | 85011012.19 | 85011012.19 | km^2 | 6 |
| 01 | 21252753.05 | 21252753.05 | 21252753.05 | km^2 | 24 |
| 02 | 4919708.23 | 6026521.16 | 5313188.26 | km^2 | 96 |
| 03 | 1055377.48 | 1646455.50 | 1328297.07 | km^2 | 384 |
| 04 | 231564.06 | 413918.15 | 332074.27 | km^2 | 1536 |
| 05 | 53798.67 | 104297.91 | 83018.57 | km^2 | 6K |
| 06 | 12948.81 | 26113.30 | 20754.64 | km^2 | 24K |
| 07 | 3175.44 | 6529.09 | 5188.66 | km^2 | 98K |
| 08 | 786.20 | 1632.45 | 1297.17 | km^2 | 393K |
| 09 | 195.59 | 408.12 | 324.29 | km^2 | 1573K |
| 10 | 48.78 | 102.03 | 81.07 | km^2 | 6M |
| 11 | 12.18 | 25.51 | 20.27 | km^2 | 25M |
| 12 | 3.04 | 6.38 | 5.07 | km^2 | 100M |
| 13 | 0.76 | 1.59 | 1.27 | km^2 | 402M |
| 14 | 0.19 | 0.40 | 0.32 | km^2 | 1610M |
| 15 | 47520.30 | 99638.93 | 79172.67 | m^2 | 6B |
| 16 | 11880.08 | 24909.73 | 19793.17 | m^2 | 25B |
| 17 | 2970.02 | 6227.43 | 4948.29 | m^2 | 103B |
| 18 | 742.50 | 1556.86 | 1237.07 | m^2 | 412B |
| 19 | 185.63 | 389.21 | 309.27 | m^2 | 1649B |
| 20 | 46.41 | 97.30 | 77.32 | m^2 | 7T |
| 21 | 11.60 | 24.33 | 19.33 | m^2 | 26T |
| 22 | 2.90 | 6.08 | 4.83 | m^2 | 105T |
| 23 | 0.73 | 1.52 | 1.21 | m^2 | 422T |
| 24 | 0.18 | 0.38 | 0.30 | m^2 | 1689T |
| 25 | 453.19 | 950.23 | 755.05 | cm^2 | 7e15 |
| 26 | 113.30 | 237.56 | 188.76 | cm^2 | 27e15 |
| 27 | 28.32 | 59.39 | 47.19 | cm^2 | 108e15 |
| 28 | 7.08 | 14.85 | 11.80 | cm^2 | 432e15 |
| 29 | 1.77 | 3.71 | 2.95 | cm^2 | 1729e15 |
| 30 | 0.44 | 0.93 | 0.74 | cm^2 | 7e18 |
Data Storage
In Pegasus, the key for data storage is combined by hashkey and sortkey: hashkey is used to determine the partition where the data is located. Data belongs to the same hashkey is stored in a logically contiguous area in the same Replica Server, and sortkey is used to sort the data in this area.
After converting the longitude and latitude coordinates to obtain the one-dimensional encoding CellId, this one-dimensional encoding can be stored as a key for GEO index data. Pegasus divides this one-dimensional encoding into two parts: hashkey and sortkey, and different byte partitioning strategies can be adopted according to actual user scenarios.
GEO index data is independent of the original data, and the two types of data are stored in different Pegasus tables. Pegasus uses GEO Client to synchronize data for the two tables, and supports access to both native Pegasus API and GEO API.
So, when using the Pegasus GEO feature, it is necessary to create two Pegasus tables: one is the original table to store the raw data written by the user, and the other is the GEO index table to store the GEO index data generated by the GEO client’s automatic conversion of raw data.
hashkey
Hashkey is composed of one-dimensional encoded prefixe. For example, in a user scenario, setting the hashkey length to 14 (1-byte face, 1-byte delimiter /, 12 byte Hilbert encoding) can achieve better performance.
So, the minimum search level is 12
CellId
|1/223320022232..................|
|-------------32 bytes-----------|
|---14 bytes--|
hashkey
sortkey
To meet the requirements of queries with different radius ranges and precisions, we put all the remaining 18 bytes of CellId into the sortkey.
- If the query is over larger radius ranges, take fewer sortkey bytes (corresponding to shorter CellId) as prefixes for data scan queries, which can reduce the number of data scans
- If the query is over smaller radius ranges or point queries, take more sortkey bytes (corresponding to longer CellId) as prefixes for data scan queries, which can reduce the range of data scans
This can maintain high flexibility for the application without modifying the underlying stored data.
When querying data within the same geographical area (such as a circular area), using shorter CellIds to query data has larger ranges and fewer queries, but yields more useless data outside the area. Using longer CellIds to query data results in smaller range of queries, resulting in less useless data outside the region, but with higher number of queries
refer to: S2 coverings
Although the area of the cell is already small enough ( < 1cm^2) at the 30th level, it is still possible for two POI data to fall into the same cell, so it is necessary to solve the key conflict problem based on CellId encoding. Pegasus combines the hashkey and sortkey of the original table and appends them to the sortkey of the GEO data table.
CellId
|1/223320022232200331010110113301|
|-------------32 bytes-----------|
|---14 bytes--||-----18 bytes----||--原始hashkey--||--原始sortkey--|
|-GEO hashkey-||-------------------GEO sortkey-------------------|
value
When using the Pegasus GEO feature, the value must be able to extract longitude and latitude, and the extract method can be found in Value Extractor.
The value of the GEO index table is exactly the same as the value of the original table, so there will be redundant data. Here, trades space for time to avoid secondary indexing.
If there is a need to store large data in a single POI data and you want to save disk space, you can manually implement secondary indexing, which means storing the key of the secondary index in the GEO value and then storing the actual large value in another table.
Data updates
set
set operation will simultaneously update the data of the two tables mentioned above, namely the Pegasus raw table data and GEO index table data, and the data generation method is also described above.
The hashkey and sortkey of the set operation are in the user’s own format and are not constrained when using the GEO APIs. The data synchronization of two tables is transparent to users and is automatically completed by the GEO client.
When using the Redis GEO API, refer to GEO API。
In the Pegasus implementation, the set operation first attempts to read and retrieve existing data. If the data does not exist, it directly writes data to both tables. If the data already exists, the old GEO index data will be cleaned up before writing new data. Because the index data <hashkey, sortkey> of new and old data may be different (i.e., the longitudes and latitudes obtained by the extractor for new and old values are different). If not cleaned up, there will be garbage and dirty data in the GEO index table, causing waste of disk space and dirty data will also be found during geographic range queries (i.e. GEORADIUS).
del
The del operation will delete data from both tables simultaneously, following the same principle above.
Data queries
Design
Geographic range queries will be converted into multiple scan operations by Pegasus, with each scan corresponding to all data scans within a CellId range. To achieve higher performance, it is necessary to reduce the total number of scan operations and the amount of data per scan operation, which means reducing the total number of CellIds and the area of a single CellId.
For example, when performing a range query with the red circle, the CellId query set with a blue blocks can be used as:
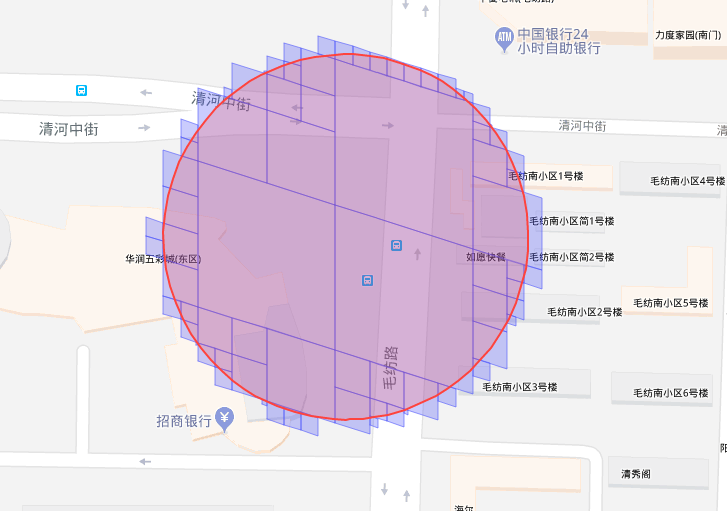
Although such results are more accurate, but there are more CellIds involved in the calculation, resulting in more client-server RPCs, higher network overhead, and higher latency. In addition, in real usage scenarios, CellId that is too small may not have POI data, but it will still consume one RPC.
So, in the current Pegasus implementation, only two levels of cells, the minimum search level and the maximum search level, are used together. Taking levels 12 and 16 as examples, the CellId query set obtained is shown in the blue blocks as:
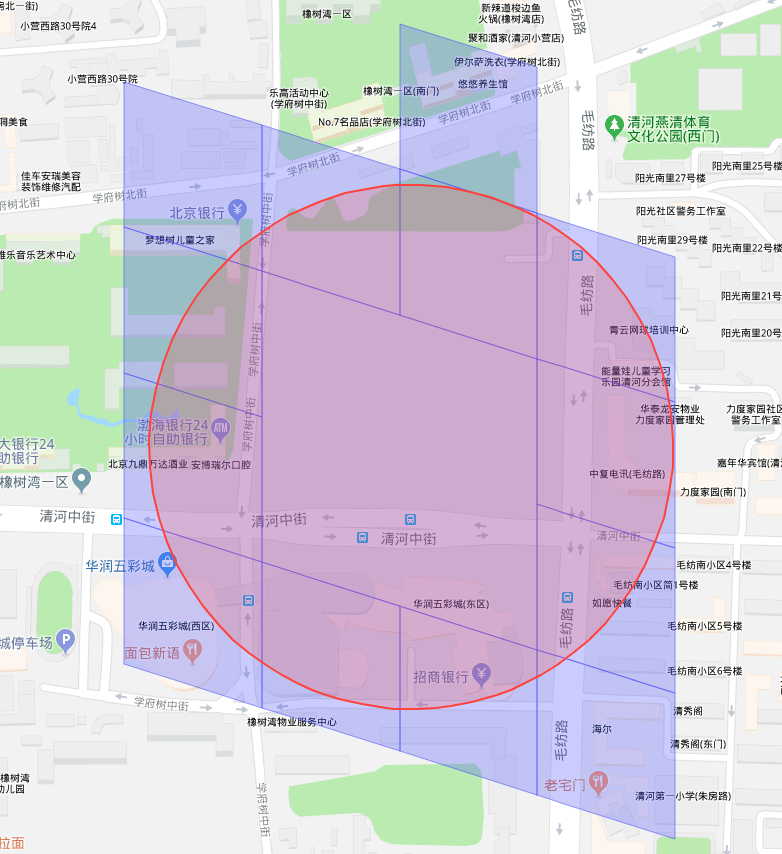
Query process
Taking search_radial as an example, it queries all POI data within the circular area according to the given center point and radius.
Here we only discuss POI data queries for circular regions, while the idea for other regions such as polygonal regions is similar.
Use the S2 API to query the CellId set that covers the given region:
// Returns an S2CellUnion that covers the given region and satisfies the current options.
S2CellUnion GetCovering(const S2Region& region);
search_radialhas two overloaded functions, one is to input longitude and latitude, and the other is to input hashky and sortkey. The latter query the value from the raw data table through the keys, extracts the longitude and latitude from the value, and then invoke the former.
Query process:
- Calculate the circular region S2Cap
Cbased on longitude, latitude, and radius - Based on the circular region and the specified
minimum search level, calculate the CellId set on theminimum search levelusingGetCovering - Traverse these CellIds to determine the relationship between the CellId region and the circular region
C- Full coverage: Retrieve all POI data within the CellId
- Half coverage: Split the CellId according to the
maximum search leveland determine the relationship between sub_CellId region and the circular regionC- Overlay/Intersection: Take all the POI data in the sub_CellId
- Disjoint: Discard
The configuration of the
minimum search leveland themaximum search levelis referred to in the following documentsThe CellId length of the
minimum search leveldetermines the hashkey length of the data in GEO index table.
When querying all the POI data of a CellId, a pair of start_sortkey and stop_sortkey will be constructed which contain all the POI data of the CellId according to the key construction rules in the previous documents, then use Pegasus’ scan interface to query data.
- For the
minimum search levelCellId encoding obtain in step3.1, it is also the hashkey of the data in GEO index table, then call Pegasusscan(CellId, "", "")to query all POI data- For example, a cell in level 12,
1/223320022232is full covered by the region, then callscan("1/223320022232", "", "")to query all POI data
- For example, a cell in level 12,
- For the sub_CellId set obtain in step
3.2.1, the hashkey is their prefix, callscan(sub_CellId_common_prefix, sub_CellId1, sub_CellId2)to query POI data- sub_CellId_common_prefix is the common prefix of the CellIds in sub_CellId set, its length is the length of hashkey. All the CellIds between sub_CellId1 and sub_CellId2 are continuous and all are in sub_CellId set, their length is the length of (
maximum search level-minimum search level) - For example, when the sub-regions
0001,0002,0003and0100of a cell in level 121/223320022232are intersect with the search region, then callscan("1/223320022232", "0001", "0003")、scan("1/223320022232", "0100", "0100")
- sub_CellId_common_prefix is the common prefix of the CellIds in sub_CellId set, its length is the length of hashkey. All the CellIds between sub_CellId1 and sub_CellId2 are continuous and all are in sub_CellId set, their length is the length of (
After obtaining the result of scan, further processing is required:
- Calculate distance: Because CellId may only partially overlap with the search region, if the POI is outside the search region, discarded it
- Sorting: When there is a requirement for ascending/descending order
Flexibility
Due to storing the complete 30 levels of CellIds, in practical use, we can adjust the maximum search level according to the geographic data density, network IO, disk IO conditions.
maximum search levelis 16 by default.
API method
dsn::error_s set_max_level(int level);
Configuration file method
[geo_client.lib]
max_level = 16
Invariance
Due to the fact that the minimum search level determines the length of the hashkey in GEO index table, once the data is written to Pegasus, the minimum search level cannot be modified because the data has been persisted according to this hashkey length rule.
The data needs to be reconstructed if modification is required.
minimum search levelis 12 by default.
[geo_client.lib]
;NOTE: 'min_level' is immutable after some data has been inserted into DB by geo_client.
min_level = 12
Value extractor
Currently, Pegasus supports extract longitude and latitude from fixed format values. Longitude and latitude are serialized as strings in value, separated by |.
For example: value can be .*|115.886447|41.269031|.*, the index of longitude and latitude in value is determined by the latitude_index and longitude_index.
API & Redis Proxy
There are two ways to use Pegasus GEO features: one is to directly use C++ GEO Client, and the other is to use Redis Proxy.
C++ GEO client codebase, there is a detailed API description.
Configuration
Please refer to the usage of Redis Proxy Redis Adaption.
The configuration files added by GEO feature are as follows:
[geo_client.lib]
;NOTE: 'min_level' is immutable after some data has been inserted into DB by geo_client.
min_level = 12
max_level = 16
; Used by 'value extractor'
latitude_index = 5
longitude_index = 4
Data import in batch
In some usage scenarios, users already has a raw data table which the values contain longitudes and latitudes, then requires constructing the GEO index table mentioned above. The copy_data function in the shell tool to achieve this. For example:
Before the copy_data operation, the target cluster and two target tables (i.e., the raw data table temp and GEO index table temp_geo) are needed to be created at first.
copy_data -c target_cluster -a temp -g
After the data import is completed, Redis Proxy can be set up, please refer to Redis Adaption. For specific instructions:
[apps.proxy]
; if using GEO APIs, an extra table name which store geo index data should be appened, i.e.
arguments = redis_cluster temp temp_geo
Benchmark
Environment
Hardware
- CPU: E5-2620v3 * 2
- Memory: 128GB
- Disk: capacity 480GB SSD * 8
- Network card: bandwidth 1Gb
Cluster
- Replica Server count:5
- Version: v1.9.2
- Partition count of the test table:128
- Single data size: 120 bytes
Testing interface
void async_search_radial(double lat_degrees,
double lng_degrees,
double radius_m,
int count,
SortType sort_type,
int timeout_ms,
geo_search_callback_t &&callback);
Parameters
- lat_degrees, lng_degrees: Select random points within the 5th-Ring Road of Beijing every query
- radius_m: The first column of the following table, in meters
- count: -1, which indicates an unlimited number of results
- sort_type: un-ordered
Result
| Radius(m) | P50(ms) | P75(ms) | P99(ms) | P99.9(ms) | Avg result count | QPS per node |
|---|---|---|---|---|---|---|
| 50 | 1.63071622 | 1.84607433 | 4.04545455 | 6.28 | 9.4608 | 740.287 |
| 100 | 1.76 | 2.33614794 | 5.4 | 6.45319149 | 38.0296 | 656.66 |
| 200 | 2.41017042 | 3.31062092 | 6.41781609 | 9.60588235 | 154.3682 | 536.624 |
| 300 | 3.30833333 | 4.21979167 | 9.4310559 | 18 | 350.9676 | 434.491 |
| 500 | 5.07763975 | 6.84964682 | 16.84931507 | 21.78082192 | 986.0826 | 347.231 |
| 1000 | 12.28164727 | 18.70972532 | 43.18181818 | 57.049698 | 3947.5294 | 204.23 |
| 2000 | 35.78666667 | 54.7300885 | 108.7331378 | 148.616578 | 15674.1198 | 98.7633 |