This document mainly introduces the concepts, usage, and design of rebalance in Pegasus.
Concept Section
In Pegasus, rebalance mainly includes the following aspects:
- If a partition has less than 3 replicas (1 primary and 2 secondaries), a node needs to be selected to complete the missing replicas. This process in Pegasus is called
cure. - After all partitions have 3 replicas each, all replicas need to be distributed evenly across the replica servers. This process in Pegasus is called
balance. - If a replica server has multiple disks mounted and provided to Pegasus through the configuration file
data_dirs, the replica server should try to keep the number of replicas on each disk at a similar level.
Based on these points, Pegasus has introduced some concepts to conveniently describe these situations:
- The Health Status of Partition
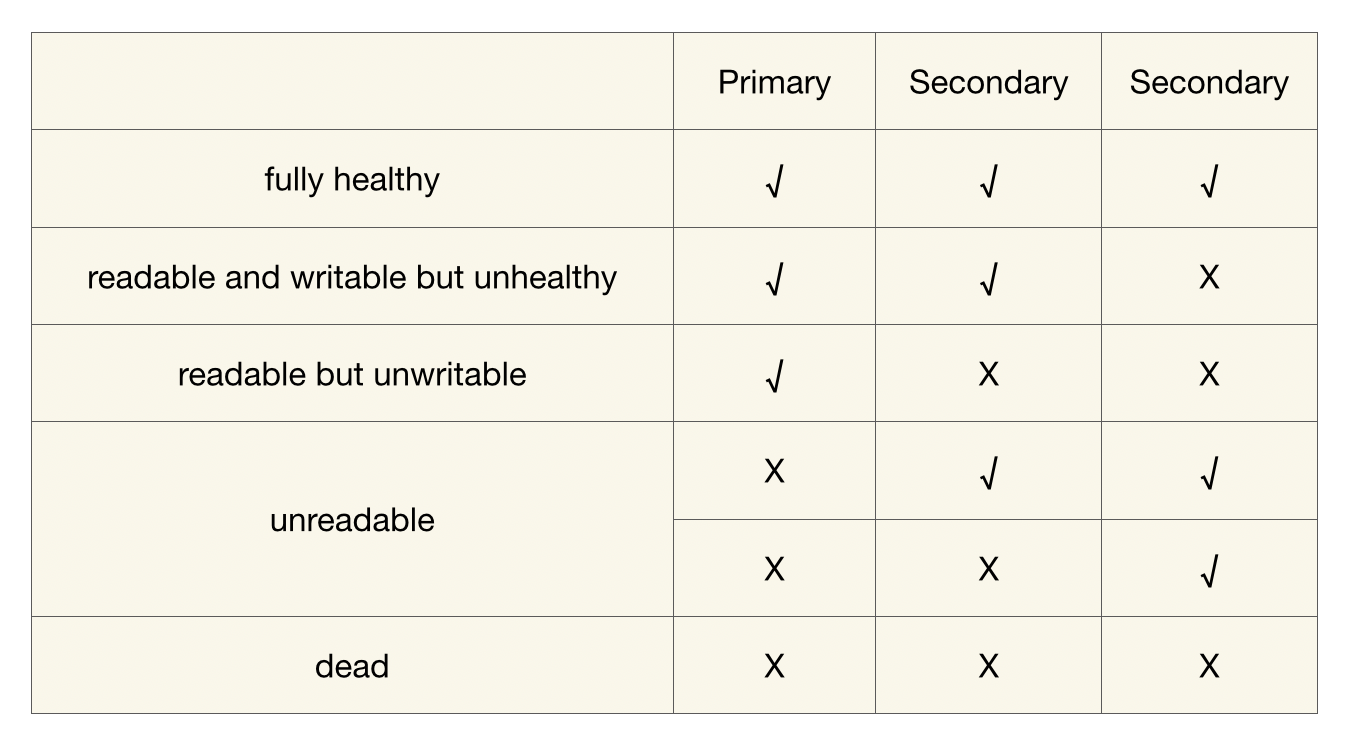
Pegasus has defined several health statuses for partitions:
- 【fully healthy】: Healthy, fully meeting the requirement of one primary and two secondaries.
- 【unreadable】: The partition is unreadable. It means that the partition lacks a primary, but there is one or two secondaries.
- 【readable but unwritable】: The partition is readable but not writable. It means that only one primary remains, and both secondary replicas are lost.
- 【readable and writable but unhealthy】: The partition is both readable and writable, but still not healthy. It means that one secondary is missing among the three replicas.
- 【dead】: All replicas of the partition are unavailable, also known as the DDD state.
When checking the status of the cluster, tables, and partitions through the Pegasus shell, you will often see the overall statistics or individual descriptions of the health conditions of the partitions. For example, by using the
ls -dcommand, you can see the number of partitions in different health conditions for each table, including the following:- fully_healthy: Completely healthy.
- unhealthy: Not completely healthy.
- write_unhealthy: Unwritable, including the above-mentioned readable but unwritable and dead states.
- read_unhealthy: Unreadable, including the above-mentioned unreadable and dead states.
- The Operating Level of the Meta Server
The operating level of the meta server determines the extent to which the meta server will manage the entire distributed system.
The most commonly used operating levels include:- blind: Under this operating level, the meta_server rejects any operation that may modify the status of the metadata. This level is generally used when migrating Zookeeper.
- steady: Under this operating level, the meta server only performs cure, that is, it only processes unhealthy partitions.
- lively: Under this operating level, once all partitions have become healthy, the meta server will attempt to perform balance to adjust the number of replicas on each machine.
Operation Section
Observing the System Status
You can observe the partition status of the system through the Pegasus shell client:
-
nodes -d
It can be used to observe the number of replicas on each node in the system:
>>> nodes -d address status replica_count primary_count secondary_count 10.132.5.1:32801 ALIVE 54 18 36 10.132.5.2:32801 ALIVE 54 18 36 10.132.5.3:32801 ALIVE 54 18 36 10.132.5.5:32801 ALIVE 54 18 36If the number of partitions on each node varies significantly, you can use the command “set_meta_level lively” to make adjustments.
-
app
-d It can be used to view the distribution of all partitions of a certain table: You can observe the composition of a specific partition, and also summarize the number of partitions of this table served by each node.
>>> app temp -d [Parameters] app_name: temp detailed: true [Result] app_name : temp app_id : 14 partition_count : 8 max_replica_count : 3 details : pidx ballot replica_count primary secondaries 0 22344 3/3 10.132.5.2:32801 [10.132.5.3:32801,10.132.5.5:32801] 1 20525 3/3 10.132.5.3:32801 [10.132.5.2:32801,10.132.5.5:32801] 2 19539 3/3 10.132.5.1:32801 [10.132.5.3:32801,10.132.5.5:32801] 3 18819 3/3 10.132.5.5:32801 [10.132.5.3:32801,10.132.5.1:32801] 4 18275 3/3 10.132.5.5:32801 [10.132.5.2:32801,10.132.5.1:32801] 5 18079 3/3 10.132.5.3:32801 [10.132.5.2:32801,10.132.5.1:32801] 6 17913 3/3 10.132.5.2:32801 [10.132.5.1:32801,10.132.5.5:32801] 7 17692 3/3 10.132.5.1:32801 [10.132.5.3:32801,10.132.5.2:32801] node primary secondary total 10.132.5.1:32801 2 4 6 10.132.5.2:32801 2 4 6 10.132.5.3:32801 2 4 6 10.132.5.5:32801 2 4 6 8 16 24 fully_healthy_partition_count : 8 unhealthy_partition_count : 0 write_unhealthy_partition_count : 0 read_unhealthy_partition_count : 0 list app temp succeed -
server_stat
It can be used to observe some current monitoring data of each replica server. If you want to analyze the balance degree of the traffic, you should focus on observing the QPS and latency of each operation. For the nodes with obviously abnormal data values (showing a large difference from other nodes), it is necessary to check whether the number of partitions is unevenly distributed, or whether there is a read-write hot spot for a certain partition.
>>> server_stat -t replica-server COMMAND: server-stat CALL [replica-server] [10.132.5.1:32801] succeed: manual_compact_enqueue_count=0, manual_compact_running_count=0, closing_replica_count=0, disk_available_max_ratio=88, disk_available_min_ratio=78, disk_available_total_ratio=85, disk_capacity_total(MB)=8378920, opening_replica_count=0, serving_replica_count=54, commit_throughput=0, learning_count=0, shared_log_size(MB)=4, memused_res(MB)=2499, memused_virt(MB)=4724, get_p99(ns)=0, get_qps=0, multi_get_p99(ns)=0, multi_get_qps=0, multi_put_p99(ns)=0, multi_put_qps=0, put_p99(ns)=0, put_qps=0 CALL [replica-server] [10.132.5.2:32801] succeed: manual_compact_enqueue_count=0, manual_compact_running_count=0, closing_replica_count=0, disk_available_max_ratio=88, disk_available_min_ratio=79, disk_available_total_ratio=86, disk_capacity_total(MB)=8378920, opening_replica_count=0, serving_replica_count=54, commit_throughput=0, learning_count=0, shared_log_size(MB)=4, memused_res(MB)=2521, memused_virt(MB)=4733, get_p99(ns)=0, get_qps=0, multi_get_p99(ns)=0, multi_get_qps=0, multi_put_p99(ns)=0, multi_put_qps=0, put_p99(ns)=0, put_qps=0 CALL [replica-server] [10.132.5.3:32801] succeed: manual_compact_enqueue_count=0, manual_compact_running_count=0, closing_replica_count=0, disk_available_max_ratio=90, disk_available_min_ratio=78, disk_available_total_ratio=85, disk_capacity_total(MB)=8378920, opening_replica_count=0, serving_replica_count=54, commit_throughput=0, learning_count=0, shared_log_size(MB)=4, memused_res(MB)=2489, memused_virt(MB)=4723, get_p99(ns)=0, get_qps=0, multi_get_p99(ns)=0, multi_get_qps=0, multi_put_p99(ns)=0, multi_put_qps=0, put_p99(ns)=0, put_qps=0 CALL [replica-server] [10.132.5.5:32801] succeed: manual_compact_enqueue_count=0, manual_compact_running_count=0, closing_replica_count=0, disk_available_max_ratio=88, disk_available_min_ratio=82, disk_available_total_ratio=85, disk_capacity_total(MB)=8378920, opening_replica_count=0, serving_replica_count=54, commit_throughput=0, learning_count=0, shared_log_size(MB)=4, memused_res(MB)=2494, memused_virt(MB)=4678, get_p99(ns)=0, get_qps=0, multi_get_p99(ns)=0, multi_get_qps=0, multi_put_p99(ns)=0, multi_put_qps=0, put_p99(ns)=0, put_qps=0 Succeed count: 4 Failed count: 0 -
app_stat -a
It can be used to observe the statistical information of each partition in a certain table. For the partitions with obviously abnormal data values, attention should be paid to whether there is a partition hot spot.
>>> app_stat -a temp pidx GET MULTI_GET PUT MULTI_PUT DEL MULTI_DEL INCR CAS SCAN expired filtered abnormal storage_mb file_count 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 0 0 0 0 4 3 0 0 0 0 0 0 0 0 0 0 0 0 0 2 4 0 0 0 0 0 0 0 0 0 0 0 0 0 3 5 0 0 0 0 0 0 0 0 0 0 0 0 0 2 6 0 0 0 0 0 0 0 0 0 0 0 0 0 1 7 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 19
Controlling the Load Balancing of the Cluster
Peagsus provides the following commands to control the load balancing of the cluster:
-
set_meta_level
This command is used to control the operating level of the meta, and the following levels are supported:
- freezed:The meta server will stop the cure work for unhealthy partitions. It is generally used when there are many nodes crashing or the cluster is extremely unstable. In addition, if the number of nodes in the cluster drops below a certain quantity or proportion (controlled by the configuration files min_live_node_count_for_unfreeze and node_live_percentage_threshold_for_update), it will automatically change to the freezed state and wait for manual intervention.
- steady:The default level of the meta server. It only performs the cure operation and does not perform the balance operation.
- lively:The meta server will adjust the number of replicas to strive for balance.
You can use either cluster_info or get_meta_level to check the current operating level of the cluster.
Some Suggestions for Adjustment:
- First, use the nodes -d command in the shell to check whether the cluster is balanced, and then make adjustments when it is unbalanced. Usually, after the following situations occur, it is necessary to enable the lively mode for adjustment:
- When a new table is created, the number of replicas may be uneven at this time.
- When nodes are launched, taken offline, or upgraded in the cluster, the number of replicas may also be uneven.
- When a node crashes and some replicas are migrated to other nodes.
- The adjustment process will trigger replica migration, which will affect the availability of the cluster. Although the impact is not significant, if the requirement for availability is very high and the adjustment demand is not urgent, it is recommended to make the adjustment during the low-peak period.
- After the adjustment is completed, reset the level to the steady state by using the
set_meta_level steadycommand to avoid unnecessary replica migration during normal times and reduce cluster jitter. - Pegasus also provides some commands for fine-grained control of balance. Please refer to Advanced Options for Load Balancing.
-
balance
The balance command is used to manually send commands for replica migration. The supported migration types are:
- move_pri: Swap the primary and secondary of a certain partition (essentially in two steps: 1. Downgrade the “from” node; 2. Upgrade the “to” node. If the meta server goes down after the first step is completed, the new meta server will not continue with the second step, and the move_pri command can be regarded as interrupted).
- copy_pri: Migrate the primary of a certain partition to a new node.
- copy_sec: Migrate the secondary of a certain partition to a new node.
Note that when using these commands, ensure that the meta server is in the steady state; otherwise, the commands will not take effect.
Please refer to the following examples (irrelevant outputs have been deleted):
>>> get_meta_level current meta level is fl_steady >>> app temp -d pidx ballot replica_count primary secondaries 0 3 3/3 10.231.58.233:34803 [10.231.58.233:34802,10.231.58.233:34801] list app temp succeed >>> balance -g 1.0 -p move_pri -f 10.231.58.233:34803 -t 10.231.58.233:34802 send balance proposal result: ERR_OK >>> app temp -d pidx ballot replica_count primary secondaries 0 5 3/3 10.231.58.233:34802 [10.231.58.233:34801,10.231.58.233:34803] list app temp succeed -
propose
The propose command is used to send replica adjustment commands at a lower primitive level, mainly including the following types:
- assign_primary:Assign the primary of a certain partition to a specific machine
- upgrade_to_primary:Upgrade the secondary of a certain partition to a primary
- add_secondary: Add a secondary for a certain partition
- upgrade_to_secondary: Upgrade a certain learner under a partition to a secondary
- downgrade_to_secondary:Downgrade the primary under a certain partition to a secondary
- downgrade_to_inactive:Downgrade the primary/secondary under a certain partition to an inactive state
- remove:Remove a certain replica under a certain partition
>>> app temp -d pidx ballot replica_count primary secondaries 0 5 3/3 10.231.58.233:34802 [10.231.58.233:34801,10.231.58.233:34803] list app temp succeed >>> propose -g 1.0 -p downgrade_to_inactive -t 10.231.58.233:34802 -n 10.231.58.233:34801 send proposal response: ERR_OK >>> app temp -d pidx ballot replica_count primary secondaries 0 7 3/3 10.231.58.233:34802 [10.231.58.233:34803,10.231.58.233:34801] list app temp succeedIn the above example, the propose command aims to downgrade 10.231.38.233:34801. Therefore, this command needs to be sent to the primary (10.231.58.233:34802) of the partition, and it will execute the specific matter of downgrading a certain replica. Note that this reflects the design concept of the Pegasus system: The meta server is responsible for managing the primary, and the primary is responsible for managing other replicas under the partition.
In the above example, there may not be an obvious sign that 10.231.38.233:34801 has been downgraded. This is due to the existence of the system’s cure function, which will quickly repair an unhealthy partition. You can confirm that the command has taken effect by observing the changes in the ballot.
Under normal circumstances, you shouldn’t need to use the propose command.
Advanced Options for Load Balancing
The meta server provides some more fine-grained parameters for load balancing control. These parameters are adjusted through the remote_command command:
You can use the help command to view all the remote_command options available.
>>> remote_command -l 127.0.0.1:34601 help
COMMAND: help
CALL [user-specified] [127.0.0.1:34601] succeed: help|Help|h|H [command] - display help information
repeat|Repeat|r|R interval_seconds max_count command - execute command periodically
...
meta.lb.assign_delay_ms [num | DEFAULT]
meta.lb.assign_secondary_black_list [<ip:port,ip:port,ip:port>|clear]
meta.lb.balancer_in_turn <true|false>
meta.lb.only_primary_balancer <true|false>
meta.lb.only_move_primary <true|false>
meta.lb.add_secondary_enable_flow_control <true|false>
meta.lb.add_secondary_max_count_for_one_node [num | DEFAULT]
...
Succeed count: 1
Failed count: 0
remote_commandThe remote_command is a feature of Pegasus, which allows a server to register some commands, and then the command line can call these commands through RPC. Here, we use the help command to access the meta server leader and obtain all the commands supported on the meta server. In the example, all irrelevant lines have been omitted, leaving only all the commands related to load balancing that start with “meta.lb”.
Due to the inconsistency between the documentation and the code, the documentation may not necessarily cover all the current load balancing (lb) control commands of the meta. If you want to obtain the latest command list, please manually execute the help command using the latest code.
assign_delay_ms
The assign_delay_ms is used to control how long we should delay before selecting a new secondary when a partition lacks one. The reason for this is that the disconnection of a replica may be temporary. If a new secondary is selected without providing a certain buffer period, it may lead to a huge amount of data copying.
>>> remote_command -t meta-server meta.lb.assign_delay_ms
COMMAND: meta.lb.assign_delay_ms
CALL [meta-server] [127.0.0.1:34601] succeed: 300000
CALL [meta-server] [127.0.0.1:34602] succeed: unknown command 'meta.lb.assign_delay_ms'
CALL [meta-server] [127.0.0.1:34603] succeed: unknown command 'meta.lb.assign_delay_ms'
Succeed count: 3
Failed count: 0
>>> remote_command -t meta-server meta.lb.assign_delay_ms 10
COMMAND: meta.lb.assign_delay_ms 10
CALL [meta-server] [127.0.0.1:34601] succeed: OK
CALL [meta-server] [127.0.0.1:34602] succeed: unknown command 'meta.lb.assign_delay_ms'
CALL [meta-server] [127.0.0.1:34603] succeed: unknown command 'meta.lb.assign_delay_ms'
Succeed count: 3
Failed count: 0
>>> remote_command -t meta-server meta.lb.assign_delay_ms
COMMAND: meta.lb.assign_delay_ms
CALL [meta-server] [127.0.0.1:34601] succeed: 10
CALL [meta-server] [127.0.0.1:34602] succeed: unknown command 'meta.lb.assign_delay_ms'
CALL [meta-server] [127.0.0.1:34603] succeed: unknown command 'meta.lb.assign_delay_ms'
Succeed count: 3
Failed count: 0
As shown in the example, when the command is executed without parameters, it indicates that the current set value will be returned. Adding parameters means specifying the expected new value.
assign_secondary_black_list
This command is used to set the blacklist for adding secondaries. This command is extremely useful when taking nodes offline in batches from the cluster.
Flow Control during the Addition of Secondaries
At some times, the decision algorithm of load balancing may require adding quite a few secondary replicas on one machine. For example:
- The crash of one or more nodes will cause normal nodes to accept a large number of partitions instantaneously.
- When a new node is added, a large number of replicas may flood in.
However, when executing these decision-making actions of adding replicas, we should avoid adding a large number of secondary shards simultaneously at the same moment, because:
- Adding secondary replicas basically involves data copying. If the quantity is too large, it may affect normal reading and writing
- The total bandwidth is limited. If multiple tasks of adding replicas are sharing this bandwidth, then the execution time of each task will be prolonged. As a result, the system will be in a state where a large number of replicas are unhealthy for a long time, increasing the risk of instability.
So, Pegasus uses two commands to support flow control:
- meta.lb.add_secondary_enable_flow_control: It indicates whether to enable the flow control feature.
- meta.lb.add_secondary_max_count_for_one_node: It represents the number of add_secondary actions that can be executed simultaneously for each node.
Fine-grained Control of the Balancer
In the current implementation of Pegasus, the balancer process can be roughly summarized in four points:
- Try to achieve the balance of primaries as much as possible through role swapping.
- If it is not possible to make the primaries evenly distributed in step 1, achieve the balance of primaries by copying data.
- After step 2 is completed, achieve the balance of secondaries by copying data.
- Perform the actions in steps 1-2-3 for each table separately.
Pegasus provides some control parameters for this process, enabling more fine-grained control:
- meta.lb.only_primary_balancer: For each table, only steps 1 and 2 are carried out (reducing the data copying caused by copying secondaries).
- meta.lb.only_move_primary: For each table, when adjusting the primary, only consider method 1 (reducing the data copying caused by copying primaries).
- meta.lb.balancer_in_turn:The balancers of various tables are executed in a sequential manner instead of in parallel (used for debugging and observing the system behavior).
Usage Examples of Some Commands
By combining the above load balancing primitives, Pegasus provides some scripts to execute operations such as rolling upgrades and node offline processes, for example:
-
This script is used to drive away all the primaries of the services running on a certain node.
-
scripts/pegasus_rolling_update.sh
It is used to perform an online rolling upgrade on the nodes in the cluster.
-
scripts/pegasus_offline_node_list.sh
It is used to take a batch of nodes offline.
However, the logic of some of the scripts depends on Xiaomi’s Minos Deployment System。Here, it is hoped that everyone can offer assistance to Pegasus and enable it to support more deployment systems.
Cluster-level Load Balancing
- The above descriptions all perform load balancing on a per-table basis. That is, when each table in a cluster is balanced on the replica servers, the meta server considers the entire cluster to be balanced.
- However, in some scenarios, especially when there are a large number of replica server nodes in the cluster and there are a large number of tables with small replicas in the cluster, even if each table is balanced, the entire cluster is not balanced.
- Starting from version 2.3.0, Pegasus supports cluster-level load balancing, ensuring that the number of replicas in the entire cluster is balanced without changing the balance of the tables.
The usage method is the same as the method described above, and it supports all the commands mentioned above.
If you need to use cluster-level load balancing, you need to modify the following configurations:
[[meta_server]]
balance_cluster = ture // default is false
Design Section
In the current implementation of the Pegasus balancer, the meta server will regularly evaluate the replica distribution across of all replica servers. When it deems that the replicas are unevenly distributed across nodes, it will migrate the corresponding replicas. The factors that need to be considered during the decision-making process of the balancer are as follows:
- For any table, the partitions should be evenly distributed across nodes, which includes the following aspects:
- The three replicas of a certain partition cannot all be located on one node.
- The number of primaries should be evenly distributed.
- The number of secondaries should also be evenly distributed.
- When it is found that the distribution of primaries is uneven, the first strategy to be considered should be to switch the roles of the primaries, rather than directly performing data copying.
- Not only should the load balancing between nodes be considered, but also the number of replicas on each disk within a node should be balanced as much as possible.
Move_Primary
When the distribution of primaries is uneven, the first strategy to be considered is to perform role switching. That is to say, it is necessary to find a path to migrate the primaries from the “side with more primaries” to the “side with fewer primaries”. Taking the number of migrated primaries as the traffic, it is natural for us to think of the Ford-Fulkerson algorithm, which is as follows:
- Find an augmenting path from the source to the sink.
- Modify the weights of each edge according to the augmenting path to form a residual network.
- Continue with step 1 in the residual network until no augmenting path can be found.
However, we cannot directly apply the Ford-Fulkerson algorithm. The reason is that in step 2, according to the Ford-Fulkerson algorithm, an edge with a weight of x on the augmenting path means that the number of primaries flowing from A to B is x. At this time, when forming the residual network, the weight of this edge needs to be subtracted by x. However, the weight of its reverse edge also increases by x simultaneously(the function of the reverse edge is to provide an opportunity for adjustment. Since the previously formed augmenting path is likely not the maximum flow, the reverse edge is used to adjust the previously formed augmenting path. For details, refer to the Ford-Fulkerson algorithm). But in our model, it is unreasonable for the reverse edge to increase by x. For example, for Partition[Primary: A, Secondary: (B, C)], when the primary flows from A to B, and finally the partition becomes [Primary: B, Secondary: (A, C)], this means that:
- The flow from A to B decreases.
- The flow from A to C decreases.
- The flow from B to A increases.
- The flow from B to C increases.
This is obviously different from the weight change of the reverse edge in the residual network of the Ford-Fulkerson algorithm. Therefore, we modify the algorithm as follows:
- Generate a graph structure according to the current partition distribution, and find an augmenting path according to the Ford-Fulkerson algorithm.
- Based on the found augmenting path, construct the decision-making action for the primary role switch, and execute this action in the cluster to generate a new partition distribution.
- According to the new partition distribution, iterate step 1 until no augmenting path can be found.
As can be seen from the above, this algorithm mainly modifies step 2, and it is not as simple as modifying the edge weights like in the Ford-Fulkerson algorithm.
NOTE:When we execute the Ford-Fulkerson algorithm for primary migration, it is carried out for a single table. That is to say, constructing the network and performing the role switch are all targeted at a single table. When it comes to migrating multiple tables, we just need to loop through and execute the above process for each of all the tables.
Copy_Primary
When an augmenting path cannot be successfully obtained, it indicates that simply achieving load balancing through role switching is no longer possible, and it is necessary to achieve it by migrating the Primary. The implementation of the Primary migration algorithm is relatively simple, and its specific execution steps are as follows:
- Sort the nodes in ascending order according to the number of Primaries to obtain the pri_queue.
- In the pri_queue, id_min always points to the head node of the pri_queue, and id_max always points to the tail node of the pri_queue, as shown in the following figure:
+------+------+------+------+------+------+------+------+ | | V V id_min id_max - For all the Primaries on the current id_max, find their corresponding disks respectively and obtain the disk loads. Select the disk with the maximum load and its corresponding Primary for migration.
- Increment the number of Primaries pointed to by the current id_min by 1 and decrement the number of Primaries pointed to by the current id_max by 1 respectively. Re-sort the nodes, and then loop through and execute the above steps until the number of Primaries on the id_min node is greater than or equal to N/M. At this point, it indicates that the balance has been achieved.
Copy_Secondary
The above has explained the load balancing of Primaries. Certainly, the load balancing of Secondaries is also necessary. Otherwise, it may occur that the Primaries on different nodes are balanced, but the total number of replicas is unbalanced. Since the role switching has already been carried out during the Primary migration, the Secondary migration is not as complicated as that of the Primaries, and there is no need to consider the issue of role switching. At this time, direct copying is sufficient. Therefore, for the load balancing of Secondaries, the same algorithm as that for copying Primaries is directly adopted, and the details will not be repeated here. Similarly, the load balancing of Secondaries also needs to be carried out for all tables separately.
NOTE: The above operations of constructing the graph, finding the augmenting path, Move_Primary, Copy_Primary, and Copy_Secondary are all carried out for a single table. For multiple tables in the cluster, the above steps need to be executed once for each table.