性能测试
测试工具及配置
- 使用YCSB中的Pegasus Java Client进行测试
- 设置
requestdistribution=zipfian,可以理解为遵守80/20原则的数据分布,即80%的访问都集中在20%的内容上。参考Zipfian distribution.
测试结果说明
- Case:分为只读测试
Read、只写测试Write、读写混合测试Read & Write - threads:写为
a * b的形式,其中a表示client的实例数,即YCSB是运行在几个节点上的。b表示线程数,即YCSB中的threadcount配置项的值 - RW Ratio:读写操作比,即YCSB配置中的
readproportion与updateproportion或insertproportion的比值 - duration:测试总时长,单位小时
- R-QPS:每秒读操作数
- R-AVG-Lat, R-P99-Lat, R-P999-Lat:读操作的平均,P99,P999延迟,单位微秒
- W-QPS:每秒写操作数
- W-AVG-Lat, W-P99-Lat, W-P999-Lat:写操作的平均,P99,P999延迟,单位微秒
各版本的性能测试
2.4.0
测试环境
硬件配置
- CPU:Intel® Xeon® Silver 4210 * 2 2.20 GHz / 3.20 GHz
- 内存:128 GB
- 磁盘:SSD 480 GB * 8
- 网卡:带宽 10 Gb
集群规模
- replica server节点数:5
- 测试表的Partition数:64
测试结果
- 单条数据大小:1KB
| Case | threads | Read/Write | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|
| Write | 3 * 15 | 0:1 | - | - | - | 56,953 | 787 | 1,786 |
| Read | 3 * 50 | 1:0 | 360,642 | 413 | 984 | - | - | - |
| Read & Write | 3 * 30 | 1:1 | 62,572 | 464 | 5,274 | 62,561 | 985 | 3,764 |
| Read & Write | 3 * 15 | 1:3 | 16,844 | 372 | 3,980 | 50,527 | 762 | 1,551 |
| Read & Write | 3 * 15 | 1:30 | 1,861 | 381 | 3,557 | 55,816 | 790 | 1,688 |
| Read & Write | 3 * 30 | 3:1 | 140,484 | 351 | 3,277 | 46,822 | 856 | 2,044 |
| Read & Write | 3 * 50 | 30:1 | 336,106 | 419 | 1,221 | 11,203 | 763 | 1,276 |
2.3.0
测试环境
同2.4.0
测试结果
| Case | threads | Read/Write | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|
| Write | 3 * 15 | 0:1 | - | - | - | 42,386 | 1,060 | 6,628 |
| Read | 3 * 50 | 1:0 | 331,623 | 585 | 2,611 | - | - | - |
| Read & Write | 3 * 30 | 1:1 | 38,766 | 1,067 | 15,521 | 38,774 | 1,246 | 7,791 |
| Read & Write | 3 * 15 | 1:3 | 13,140 | 819 | 11,460 | 39,428 | 863 | 4,884 |
| Read & Write | 3 * 15 | 1:30 | 1,552 | 937 | 9,524 | 46,570 | 930 | 5,315 |
| Read & Write | 3 * 30 | 3:1 | 93,746 | 623 | 6,389 | 31,246 | 996 | 5,543 |
| Read & Write | 3 * 50 | 30:1 | 254,534 | 560 | 2,627 | 8,481 | 901 | 3,269 |
1.12.3
测试环境
硬件配置
- CPU:Intel® Xeon® CPU E5-2620 v3 @ 2.40 GHz
- 内存:128 GB
- 磁盘:SSD 480 GB * 8
- 网卡:带宽 10 Gb
其他测试环境同2.4.0
测试结果
- 单条数据大小:320B
| Case | threads | Read/Write | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|
| Read & Write | 3 * 15 | 0:1 | - | - | - | 41,068 | 728 | 3,439 |
| Read & Write | 3 * 15 | 1:3 | 16,011 | 242 | 686 | 48,036 | 851 | 4,027 |
| Read & Write | 3 * 30 | 30:1 | 279,818 | 295 | 873 | 9,326 | 720 | 3,355 |
- 单条数据大小:1KB
| Case | threads | Read/Write | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|
| Read & Write | 3 * 15 | 0:1 | - | - | - | 40,732 | 1,102 | 4,216 |
| Read & Write | 3 * 15 | 1:3 | 14,355 | 476 | 2,855 | 38,547 | 1,016 | 4,135 |
| Read & Write | 3 * 20 | 3:1 | 87,480 | 368 | 4,170 | 29,159 | 940 | 4,170 |
| Read & Write | 3 * 50 | 1:0 | 312,244 | 479 | 1,178 | - | - | - |
1.12.2
测试环境
测试环境同 1.12.3
测试结果
- 单条数据大小:320B
| Case | threads | Read/Write | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|
| Read & Write | 3 * 15 | 0:1 | - | - | - | 40,439 | 739 | 2,995 |
| Read & Write | 3 * 15 | 1:3 | 16,022 | 309 | 759 | 48,078 | 830 | 3,995 |
| Read & Write | 3 * 30 | 30:1 | 244,392 | 346 | 652 | 8,137 | 731 | 2,995 |
1.11.6
测试环境
- 测试接口:
multi_get()和batch_set() - 一个hashkey下包含3条sortkey数据
- 单次
batch_set()调用设置3个hashkey - 单条数据大小:3KB
- 测试表的Partition数:128
- rocksdb_block_cache_capacity = 40G
- 其他测试环境同 1.12.3
测试结果
| Case | threads | Read/Write | duration | Max cache hit rate | R-QPS | R-AVG-Lat | R-P99-Lat | R-P999-Lat | W-QPS | W-AVG-Lat | W-P99-Lat | W-P999-Lat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Read & Write | 3 * 15 | 20:1 | 1 | 10% | 150K | 263 | 808 | 12,615 | 8k | 1,474 | 7,071 | 26,342 |
| Read & Write | 3 * 7 | 20:1 | 2 | 17% | 75K | 226 | 641 | 5,331 | 4K | 1,017 | 4,583 | 14,983 |
1.11.1
测试环境
测试环境同 1.12.3
测试结果
- 单条数据大小:20KB * 2副本
| Case | threads | Read/Write | duration | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|---|
| Write | 3 * 10 | 0:1 | 0.98 | - | - | - | 8,439 | 3,557 | 32,223 |
| Read & Write | 3 * 15 | 1:3 | 0.66 | 3,159 | 4,428 | 34,495 | 9,472 | 3,251 | 25,071 |
| Read & Write | 3 * 30 | 30:1 | 1.25 | 64,358 | 1,330 | 13,975 | 2,145 | 1,699 | 6,467 |
| Read | 6 * 100 | 1:0 | 0.91 | 30,491 | 3,274 | 12,167 | - | - | - |
- 单条数据大小:20KB * 3副本
| Case | threads | Read/Write | duration | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|---|
| Write | 3 * 10 | 0:1 | 1.40 | - | - | - | 5,919 | 5,063 | 40,639 |
| Read & Write | 3 * 15 | 1:3 | 1.11 | 1,876 | 6,927 | 44,639 | 5,632 | 5,612 | 76,095 |
| Read & Write | 3 * 30 | 30:1 | 1.63 | 49,341 | 1,751 | 21,615 | 1,644 | 1,935 | 11,159 |
| Read | 6 * 100 | 1:0 | 0.91 | 25,456 | 3,923 | 15,679 | - | - | - |
- 单条数据大小:10KB * 2副本
| Case | threads | Read/Write | duration | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|---|
| Write | 3 * 10 | 0:1 | 0.78 | - | - | - | 14,181 | 2,110 | 15,468 |
| Read & Write | 3 * 15 | 1:3 | 0.52 | 4,024 | 5,209 | 41247 | 12,069 | 1,780 | 14,495 |
| Read & Write | 3 * 30 | 30:1 | 0.76 | 105,841 | 816 | 9613 | 3,527 | 1,107 | 4,155 |
| Read | 6 * 100 | 1:0 | 1.04 | 162,150 | 1,868 | 6733 | - | - | - |
- 单条数据大小:10KB * 3副本
| Case | threads | Read/Write | duration | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|---|
| Write | 3 * 10 | 0:1 | 1.16 | - | - | - | 9,603 | 3,115 | 20,468 |
| Read & Write | 3 * 15 | 1:3 | 0.69 | 3,043 | 5,657 | 38,783 | 9,126 | 3,140 | 27,956 |
| Read & Write | 3 * 30 | 30:1 | 0.89 | 90,135 | 937 | 13,324 | 3,002 | 1,185 | 4,816 |
| Read | 6 * 100 | 1:0 | 1.08 | 154,869 | 1,945 | 7,757 | - | - | - |
1.11.0
测试环境
测试环境同 1.12.3
测试结果
- 单条数据大小:320B
| Case | threads | Read/Write | duration | R-QPS | R-AVG-Lat | R-P99-Lat | W-QPS | W-AVG-Lat | W-P99-Lat |
|---|---|---|---|---|---|---|---|---|---|
| Write | 3 * 10 | 0:1 | 1.89 | - | - | - | 44,039 | 679 | 3,346 |
| Read & Write | 3 * 15 | 1:3 | 1.24 | 16,690 | 311 | 892 | 50,076 | 791 | 4,396 |
| Read & Write | 3 * 30 | 30:1 | 1.04 | 311,633 | 264 | 511 | 10,388 | 619 | 2,468 |
| Read | 6 * 100 | 1:0 | 0.17 | 978,884 | 623 | 1,671 | - | - | - |
| Read | 12 * 100 | 1:0 | 0.28 | 1,194,394 | 1,003 | 2,933 | - | - | - |
不同场景下的性能测试
如无特殊说明,测试环境如下:
- 测试环境同 1.12.3
- 单条数据大小:1KB
- 客户端:
- 节点数:3
- 版本号:1.11.10-thrift-0.11.0-inlined-release
- 服务端:
- 节点数:5
- 版本号:1.12.3
- 表分片数:64
- 配置:
rocksdb_limiter_max_write_megabytes_per_sec = 500,rocksdb_limiter_enable_auto_tune = false
集群吞吐能力
该项测试旨在对比在同一集群在不同client请求吞吐下的延迟变化。
注意:未开启RocksDB限速
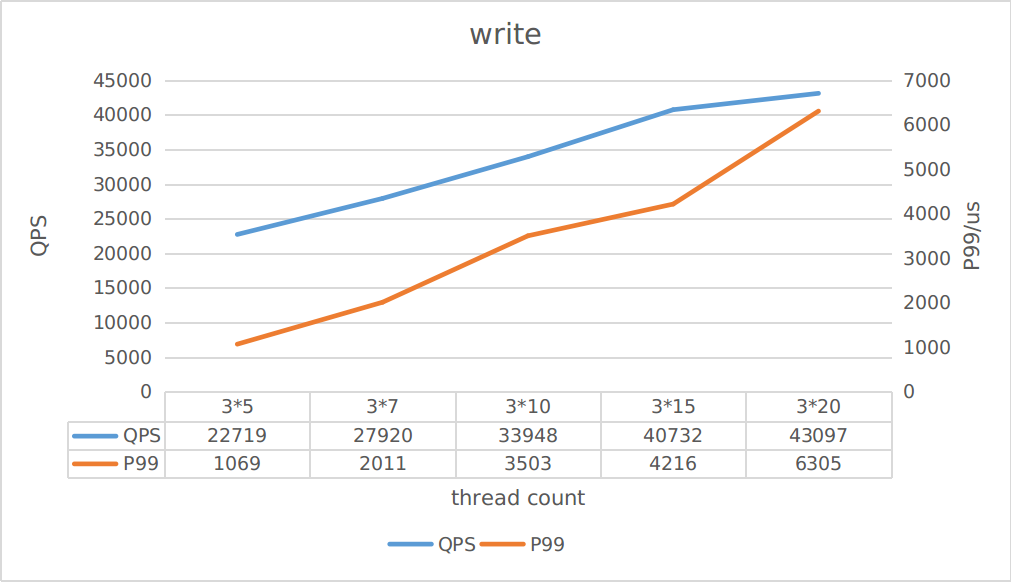
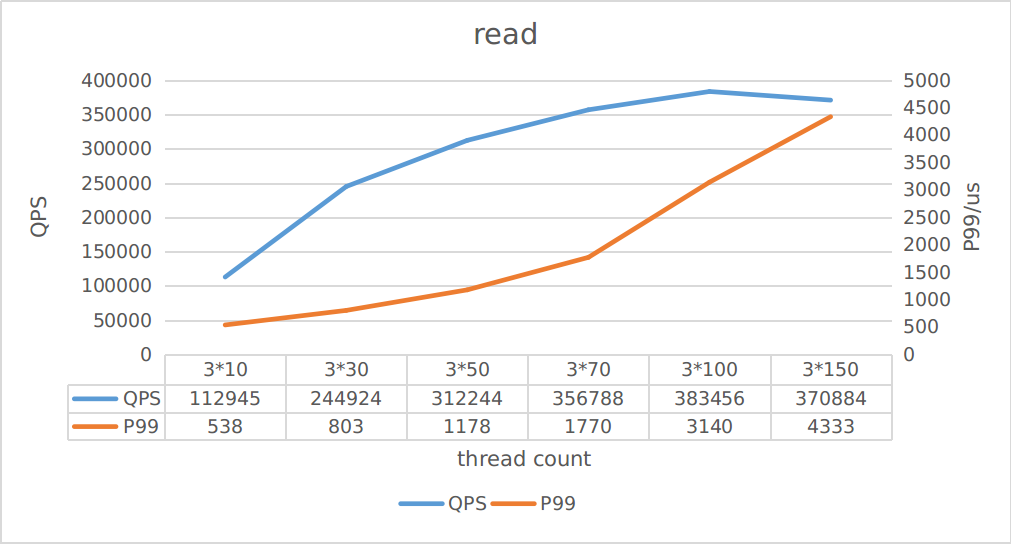
由上图可知,写最大QPS大约为43K,读最大QPS大约370K,你可以根据吞吐估算对应的延迟。
是否开启RocksDB限速
测试场景为:测试
threads配置为:3 * 20,IPS大约为44K
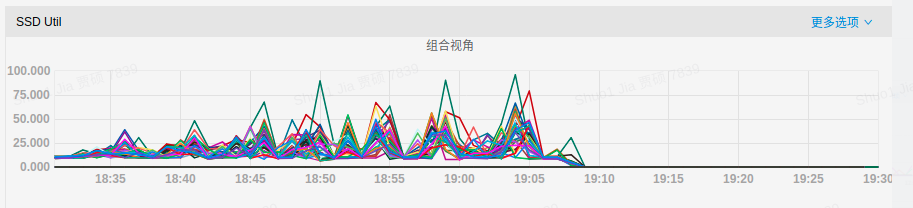
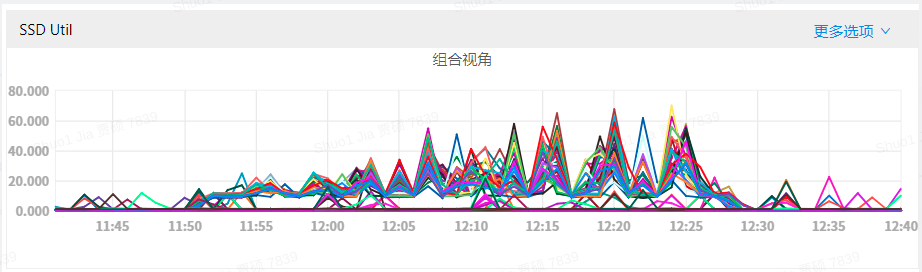
Pegasus底层采用RocksDB做存储引擎,当数据写入增多,会触发更多的compaction操作,占用更多的磁盘IO,出现更多的毛刺现象。该项测试展示了开启RocksDB的限速后,可以降低compaction负载,从而显著的降低毛刺现象。
下图分别展示了三种场景的IO使用率和写P99延迟情况:
rocksdb_limiter_max_write_megabytes_per_sec = 0rocksdb_limiter_max_write_megabytes_per_sec = 500androcksdb_limiter_enable_auto_tune = false-
rocksdb_limiter_max_write_megabytes_per_sec = 500androcksdb_limiter_enable_auto_tune = true -
磁盘IO占用:
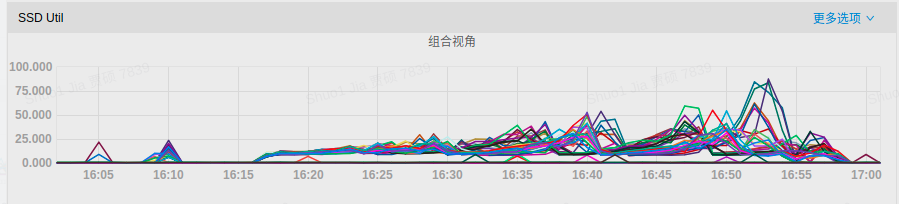
- P99延迟:
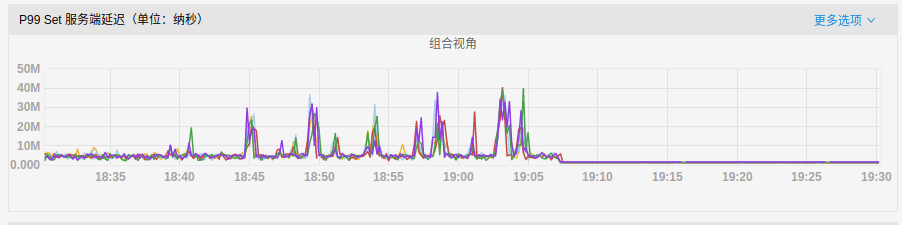
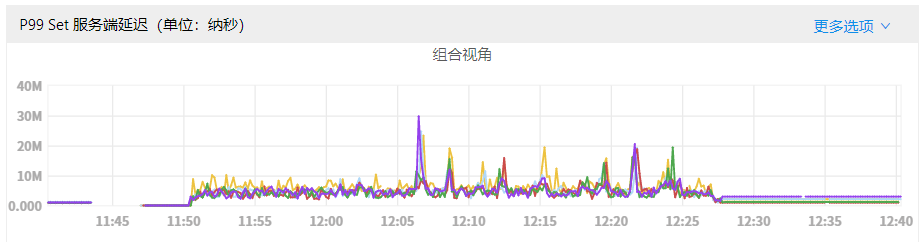
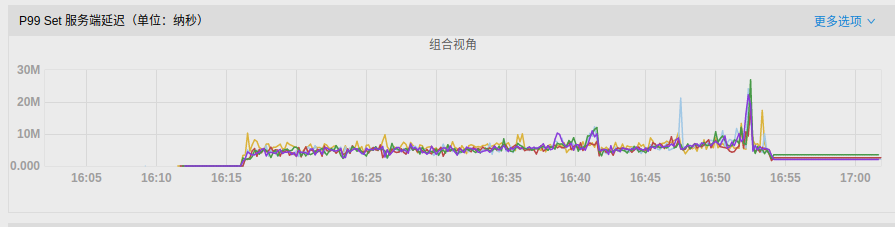
可以发现,开启RocksDB限速后,磁盘IO使用率得到降低,写延迟的毛刺现象也被大大缓解。
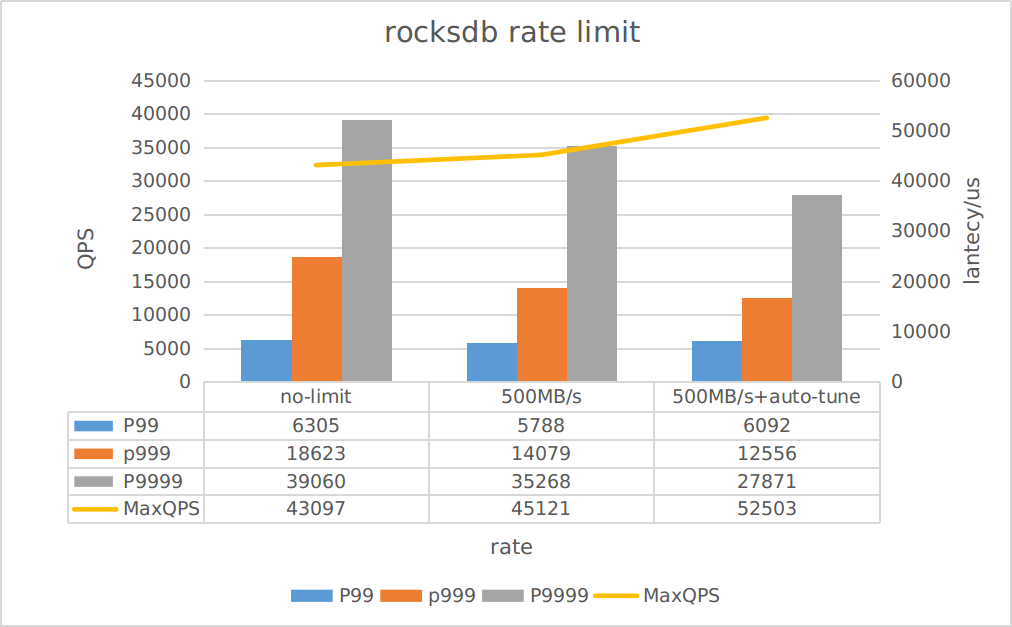 我们从YCSB的测试结果也可以看到:
我们从YCSB的测试结果也可以看到:
- 开启限速后,吞吐提升了约5%
- 开启限速并开启auto-tune后,吞吐提升了约20%
- 开启限速后,仅对极端情况下的延迟(P999/P9999)有显著改善作用,但对于大部分请求来说,改善并不明显
但是需要注意的是:
auto-tune功能在单条数据较大的场景下可能会引发write stall,请合理评估是否在你的环境中开启auto-tune。
集群规模
该项测试旨在观察,不同replica server数量对读写吞吐的影响。
测试场景为:测试
Case为只读和只写
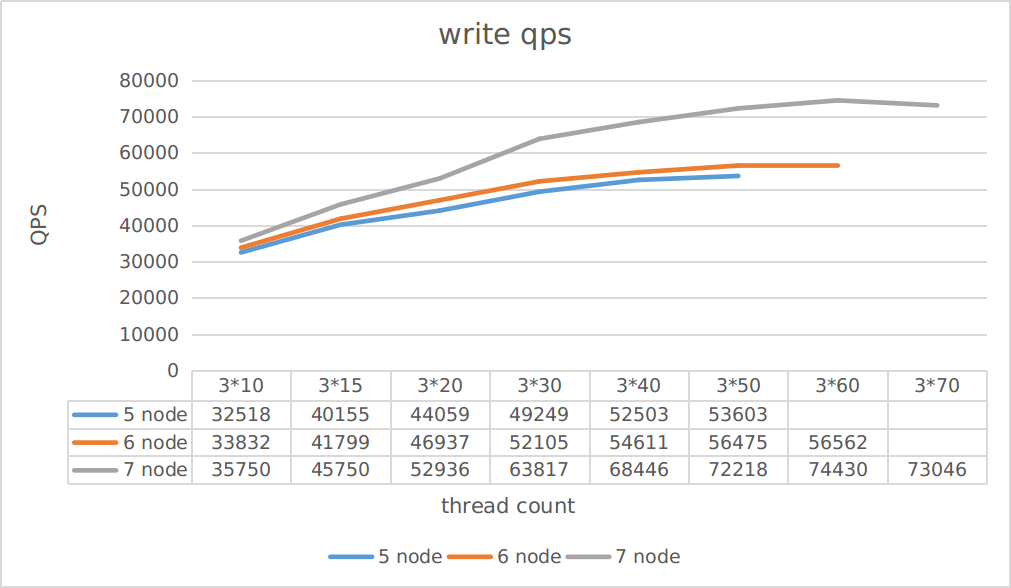
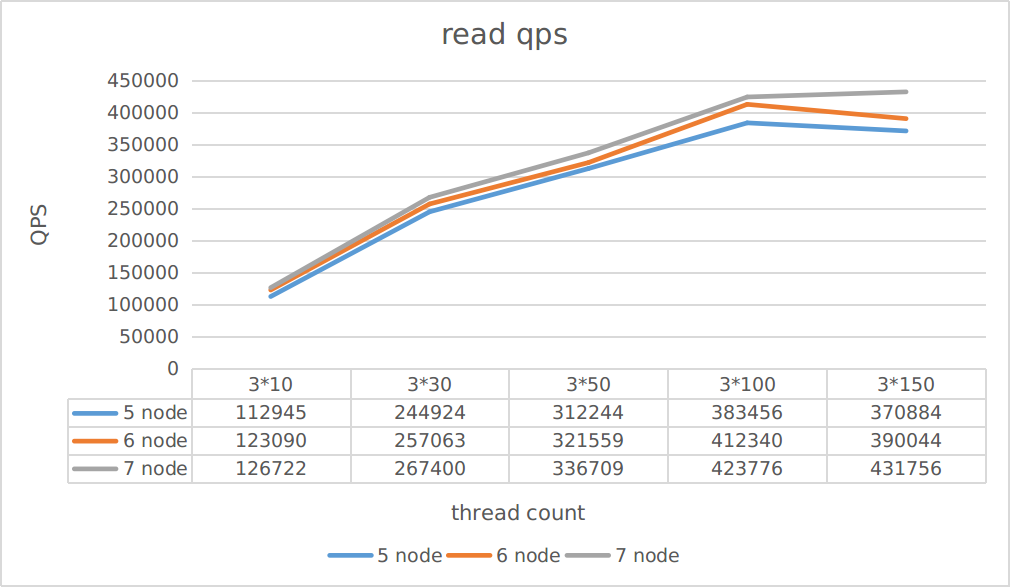
由图中可以看到:
- 扩容对写吞吐的提升要优于读吞吐的提升
- 扩容带来的吞吐提升并不是线性的
你可以根据该项测试估计不同集群规模所能承载的吞吐量
不同的表分片数
该项测试旨在观察,表的不同分片对吞吐的影响。
测试场景为: 仅读:
threads配置为:3 * 50 仅写:threads配置为:3 * 40
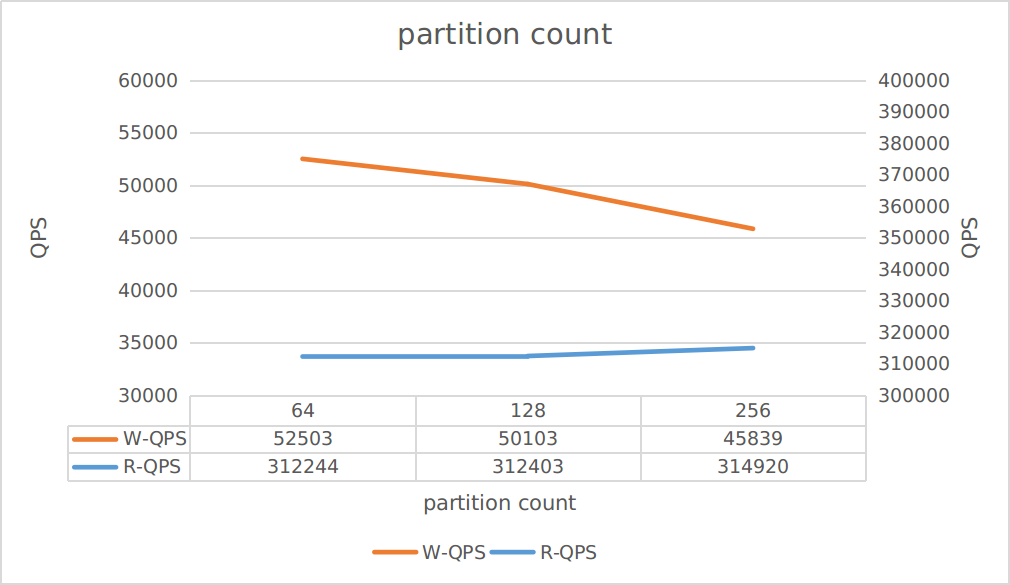
由图中可以看到:
- 增加分片可以提高读吞吐
- 但是降低了写吞吐
所以请根据你的业务需求评估表分片数。
除此之外,若分片数过小,可能会导致单分片过大,磁盘分布倾斜等问题。在生产环境中,如无特别需求,建议单分片大小保持在10GB以内。